- نخبة آسيا: بهدفي "سالم" و"كايو" في مرمى الغرافة.. الهلال يتربع على القمة
- مهلة أخيرة للمكاتب الهندسية لتوفيق أوضاعها في بلدي أعمال
- غزة بعد الاتفاق.. شهداء وجرحى بالقطاع والاحتلال يغلق محور فيلادلفيا
- شبكة أطباء السودان: تعطل شبه كامل للمستشفيات في الفاشر
- رونالدو يفوز بجائزتين في الدوري السعودي.. ما هما؟
- 6 مليارات ريال تداولات الأسهم
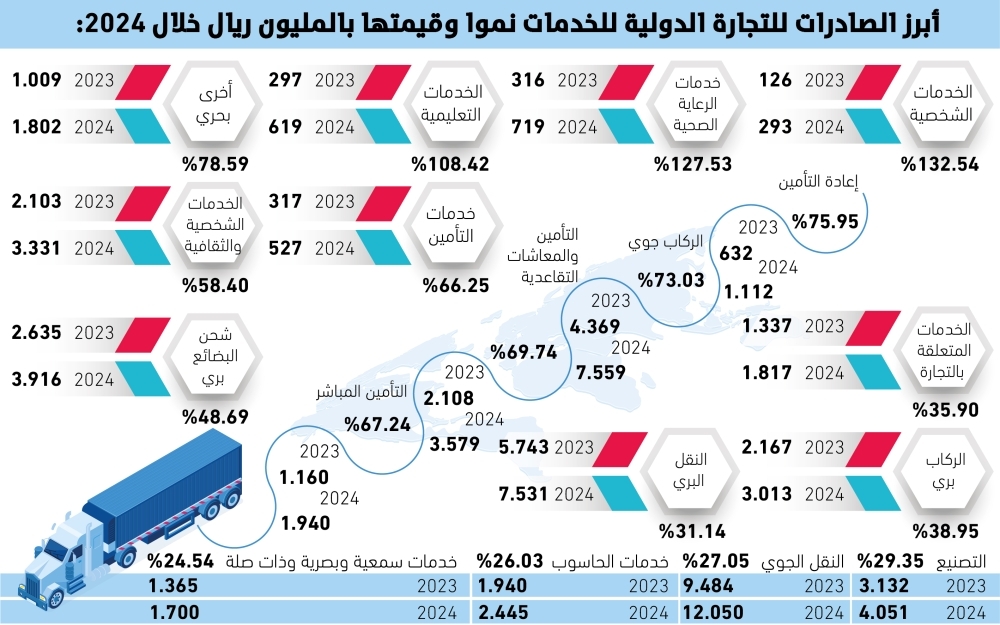
- 30.8 مليار ريال زيادة بقيمة الصادرات السعودية في قطاع الخدمات
- وزير المهجرين اللبناني: الدبلوماسية مع إسرائيل هي الأفضل
- والي جنوب دارفور: لا تفاوض ولا اتصال مع الدعم السريع
- حرب غزة: المدعية العسكرية المستقيلة تخضع للتحقيق، وغموض حول مسار مُساءلة الجنود
- إسرائيل تستعد لهجوم ضد حزب الله بسبب "تجهيزاته العسكرية"
- تضارب بشأن مصير مقاتلي حماس بمناطق سيطرة الاحتلال
- الهلال السعودي يهزم الغرافة القطري في أبطال آسيا للنخبة
- هل تدفع سيطرة قوات الدعم السريع على الفاشر إلى تقسيم السودان؟
- كيف سيتعامل ترامب مع فوز ممداني؟.. 5 سيناريوهات محتملة
- لبنان يتسلم من ليبيا ملف التحقيق في اختفاء موسى الصدر
- خامنئي: لا تعاون مع أميركا ما دامت تدعم إسرائيل
- صحيفة إسرائيلية: نتنياهو يذبح البقرة المقدسة
ما العلاقة بين أخطاء "آيفون" في التصحيح التلقائي والذكاء الاصطناعي؟
If you're making more typos in iOS lately, you're not going crazy – it's a bug in iOS that causes the keyboard to randomly insert the wrong letter instead of what you typed. pic.twitter.com/FqZOFvR4TV
— Michi (@NekoMichiUBC) October 19, 2025
غزت شكاوى المستخدمين من أخطاء التصحيح التلقائي في أنظمة " آبل " خلال الأيام الماضية، وتحديدا بعد التحديث الأخير الذي أطلقته "آبل" لأنظمة "آي أو إس 26".
ولم يقتصر الأمر فقط على منصات التواصل الاجتماعي، إذ توجه بعض المستخدمين مباشرة إلى "آبل" خوفا من أن يكون العطب في أجهزتهم فقط، وظهرت العديد من الشكاوى في منتدى المستخدمين والدعم الفني للشركة.
ولكن لماذا تعطل التصحيح التلقائي في أجهزة "آبل" فجأة؟ وهل يمكن أن يحدث هذا مع بقية الأنظمة والأجهزة أم يقتصر على "آبل"؟
آليات مختلفة مع جوهر واحد
يرى جان بيدرسن رائد التصحيح التلقائي في أنظمة " مايكروسوفت " أن هناك العديد من أنظمة التصحيح التلقائي، ولا يمكن بالتحديد معرفة المنظومة التي تستخدمها "آبل" من الخارج ودون النظر إلى الأكواد البرمجية الخاصة بالنظام.
ويتفق معه كينيث تشرش عالم اللغويات الحاسوبية الذي ساهم في تطوير أقدم طرق التصحيح التلقائي في تسعينات القرن الماضي، ويضيف قائلا " تحافظ آبل على أسرارها بشكل جيد، فهي إحدى أفضل الشركات في الحفاظ على أسرارها".
ورغم غموض منظومة التصحيح التلقائي التي تعتمد عليها "آبل" في أنظمتها، فإنها تظل متشابهة في المبدأ مع بقية آليات التصحيح التلقائي.
وتعتمد أنظمة التصحيح التلقائي الحالية على مزيج من علم الإحصاء والعلوم اللغوية للحاسوب، إذ يقوم النظام بفهم سياق الحديث والنصوص الأخرى المكتوبة في المحادثة أو المستند، وبعد ذلك يقيم ويضع احتمالات استخدام كل كلمة وما تقصده.
ويعني هذا أن النظام نفسه قد لا يفهم الفارق بين الكلمات المختلفة، ولكنه يستطيع توقع الكلمة التي ترغب في استخدامها، فمثلا إن كتبت كلمة بشكل خاطئ تماما، ولكنها تتشابه في النطق مع كلمة ما وتتشابه في الكتابة مع كلمة أخرى، فإن نظام التصحيح التلقائي يعيد قراءة ما كتبته سابقا، ثم يقيم أي كلمة أقرب وأكثر اتساقا مع مجريات المحادثة أو محتويات النص.
وتعد أنظمة التصحيح التلقائي النسخة المتطورة من أنظمة أخرى أكثر بدائية، وهي أنظمة التدقيق الإملائي التي تتأكد من كتابة الكلمات المختلفة بشكل صحيح دون النظر إلى السياق العام المذكور في المحادثة أو النص.
كما أنها النواة الأولى لما نعرفه اليوم باسم نماذج اللغة العميقة التي أدت لظهور "شات جي بي تي" وغيرها من روبوتات الدردشة، فهي في النهاية تعتمد على المفهوم والفكرة ذاتها.
نواة بدائية
ظهرت آليات التدقيق الإملائي للمرة الأولى في عام 1970 مع نظام تشغيل "يونكس" الذي كان النواة الأولى لأنظمة التشغيل التي نعرفها اليوم.
وقتها، كان النظام يعرض قائمة تضم جميع الكلمات التي تمت كتابتها بشكل خاطئ إملائيا داخل أي مستند يقوم بتدقيقه، وذلك بعد أن يقوم بمطابقة المستندات مع قاموس مبني داخله، وتعد آلية العمل هذه الأكثر بدائية، إذ كان النظام يقارن فقط الكلمات دون النظر إلى سياقها أو أي شيء آخر.
 مصدر الصورة
مصدر الصورة
ويروي تشرش تجربته في تطوير أنظمة التدقيق الإملائي مع معامل "بيل" (Bell) قائلا "كان أول ما فعلته هو الحصول على حقوق استخدام القواميس البريطانية".
وتمثل هذه القواميس أول نوع من أنواع البيانات التي تم تدريب أنظمة الحواسيب عليها، وتحديدا منظومة التدقيق الإملائي، وفي البداية كانت تعتمد بشكل رئيسي على المقارنة المباشرة بين كلمات القاموس والمستندات، ولاحقا مع تطور آليات الذاكرة والتخزين تم تخزينها في ذاكرة الحواسيب لتتم العملية بشكل أسرع.
ومع تطور القدرات الحوسبية للأجهزة المختلفة، ظهر نوع جديد من آليات التدقيق والتصحيح التلقائي، وهو ما يعرف باسم "إن-غرامز" (N-Grams).
عصر ما قبل الذكاء الاصطناعي
ظلت تقنية "إن-غرامز" أحدث وأقوى ما وصلت إليه المعامل التكنولوجية، كما كانت تؤدي الغرض منها بشكل مذهل جعل المستخدمين يعتمدون عليها ولا يخشون الأخطاء الإملائية أو حتى كتابة كلمات غير مناسبة للسياق.
وتمزج هذه التقنية بشكل أساسي بين آليات التدقيق الإملائي والاحتمالات الإحصائية، أي أنها كانت تتوقع الكلمة التي تقصدها بناء على معدل استخدام هذه الكلمات لدى المستخدمين الآخرين.
 مصدر الصورة
مصدر الصورة
ثم تعرض عليك كل هذه الاختلافات والتغييرات، وتظهر الرسالة الشهيرة "هل كنت تقصد كذا؟" وهي الرسالة ذاتها التي كانت تظهر في محرك بحث "غوغل" والنواة الأولى لنماذج اللغة العميقة.
استخدام الذكاء الاصطناعي في التصحيح التلقائي
جاءت نماذج الذكاء الاصطناعي اللغوية لتكون التطور الأحدث على منظومة التصحيح التلقائي التي بدأت للمرة الأولى في عام 1970، فبدلا من أن تقارن الآلية بين الكلمة التي قمت بإدخالها بالخطأ وما يماثلها، فإنها تتوقع الكلمة التالية لما قمت بكتابته.
ويتم هذا التوقع بناء على تحليل مئات الملايين والمليارات من الكلمات والنصوص مختلفة المصادر، بدلا من الاعتماد فقط على القواميس اللغوية.
وبناء على التصريح الذي قدمته "آبل" لصحيفة "غارديان"، فإنها الآن تعتمد على نموذج لغوي خاص بها ومثبت داخل أجهزتها بشكل رئيسي.
تقنية أعقد من مجرد التصحيح التلقائي
يؤكد تصريح "آبل" أنها تستخدم الذكاء الاصطناعي بشكل أساسي في منظومة التصحيح التلقائي، وهو استخدام أكبر وأعقد من مجرد التصحيح التلقائي.
ولكن لكونها "آبل" فهي تحافظ على سرية وخصوصية التقنيات التي تقوم باستخدامها، لذلك لا توجد معلومة مؤكدة حول الآلية الجديدة التي تستخدمها الشركة.
ويمكن القول بأن "آبل" وضعت نسخة مصغرة من "شات جي بي تي" الخاص بها داخل هاتفك، وهذه النسخة مسؤولة بشكل رئيسي عن آليات التصحيح التلقائي.
وعند سؤالها عن المشاكل التي تواجه المستخدمين حاليا، أكدت "آبل" للـ"غارديان" أن المشكلة ليست في آلية التصحيح التلقائي، بل متعلقة بخطأ برمجي في لوحة المفاتيح وهي تعمل على حلها.
 المصدر:
الجزيرة
المصدر:
الجزيرة