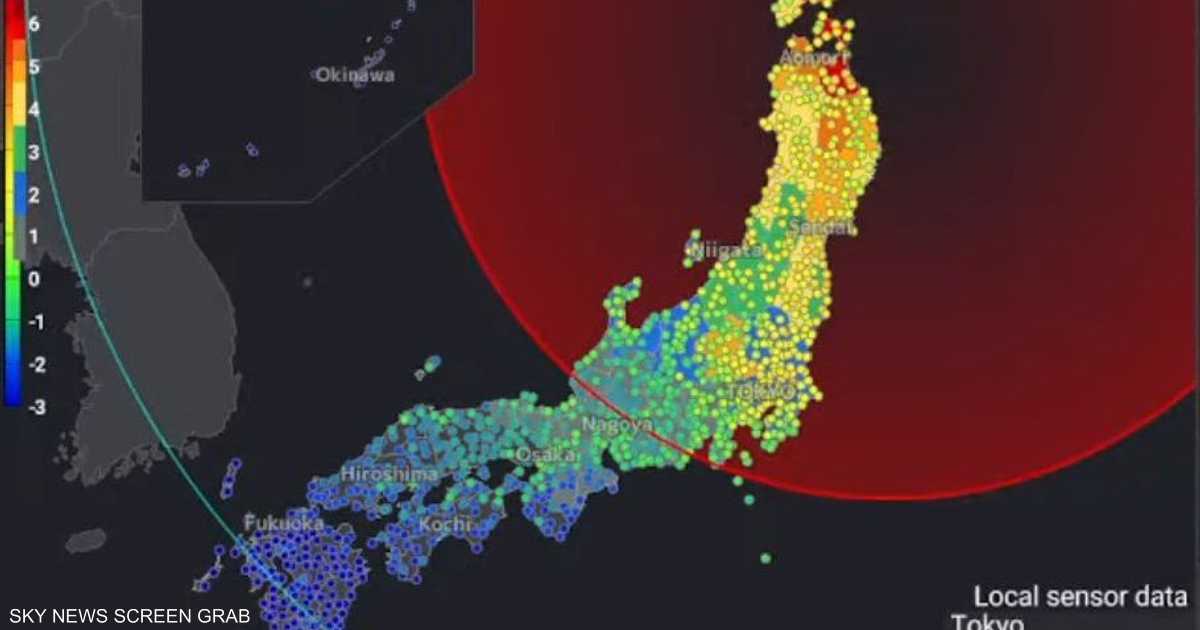
- بعد زلزال اليابان.. مخاوف من تسونامي "قاتل"
- بعد عام من الهروب إلى روسيا.. أين أصبح "ملف الأسد"؟
- بعد الأزمة.. ليفربول يعلن موقف صلاح من "رحلة إيطاليا"
- هجليج: ماذا تعني "سيطرة" قوات الدعم السريع على أكبر حقل نفطي في البلاد؟
- الشرع يتحدث عن العلاقات مع مصر والعراق
- فيديو.. موجة عملاقة تباغت السباحين وتبتلع 4 منهم
- مباشر مباراة السعودية ضد المغرب بكأس العرب 2025
- الحبس لنجم كرة إنجليزي سابق بسبب "منشورات"
- "الحدود الجديدة" بين غزة وإسرائيل.. كيف تضرب خطة ترامب؟
- تايلاند وكمبوديا: فرار الآلاف على حدود الجارتين بعد أخطر اشتباكات دامية منذ وقف إطلاق النار
- الشرع: وضعنا رؤية لسوريا قوية وملتزمون بالعدالة الانتقالية
- غزة.. انتهاء البحث عن جثة أسير إسرائيلي والاحتلال يقتحم مقرا للأونروا
- كاتب بهآرتس: إعلام إسرائيل يستخف بالفلسطينيين ويكرس الأبارتايد
- مصدر سوداني للجزيرة نت: إثيوبيا تدرّب الدعم السريع وتمده عسكريا
- المنصات تحتفي بمرور عام على سقوط الأسد
- تحذير ياباني من تسونامي بعد زلزال بقوة 7.6 درجة ريختر
- استراحات ترطيب للاعبين بكأس العالم 2026
- اليابان تحذر من تسونامي بعد زلزال بقوة 7.6 درجات
%30 من استخدام العالم لنماذج الذكاء الاصطناعي المفتوحة يعتمد على الصين

شهدت نماذج الذكاء الاصطناعي المفتوحة المصدر الصينية قفزة غير متوقعة هذا العام، حيث شكلت نحو 30% من إجمالي استخدام الذكاء الاصطناعي على مستوى العالم، بينما احتلت اللغة الصينية المرتبة الثانية بعد الإنجليزية من حيث حجم البيانات المعالجة، وفق تقرير حديث.
وأفاد التقرير، الصادر عن "OpenRouter" وبدعم من شركة رأس المال الاستثماري Andreessen Horowitz، بأن النماذج الصينية، وعلى رأسها سلسلة Qwen من مجموعة "علي بابا"، ونموذج DeepSeek V3، وKimi K2 من Moonshot AI، لعبت دوراً رئيسياً في هذا النمو السريع.
في المقابل، استمرت النماذج الغربية الخاصة مثل GPT-4o وGPT-5 في السيطرة على السوق بنسبة 70% عالمياً، بحسب تقرير نشره موقع "scmp" واطلعت عليه "العربية Business".
بحسب الدراسة التي حللت نحو 100 تريليون وحدة بيانات (Tokens)، ارتفعت الحصة العالمية للنماذج الصينية من 1.2% في أواخر 2024 إلى نحو 30% خلال الأشهر الأولى من 2025، ما يعكس توسعاً سريعاً في اعتمادها عالمياً.
كما بلغ متوسط استخدام النماذج الصينية الأسبوعي نحو 13%، مقترباً من متوسط النماذج العالمية البالغ 13.7%، مع تسارع النمو في النصف الثاني من العام.
وأشار التقرير إلى أن النمو الصيني لا يقتصر على السوق المحلي فقط، بل يعكس قدرة تنافسية عالية، وتكراراً سريعاً في الإصدارات، وجدولة إطلاق كثيفة للنماذج مثل Qwen و"ديب سيك" ما ساعد المستخدمين على التكيف سريعًا مع أعباء التطوير المتزايدة.
كما أظهرت البيانات ارتفاع الطلب على النماذج المفتوحة المصدر الصينية، ما جعل اللغة الصينية ثاني أكثر اللغات استخداماً في الطلبات على الذكاء الاصطناعي، بحصة تقارب 5% من إجمالي الطلبات، مقارنة بـ1.1% فقط من نصوص الإنترنت باللغة الصينية، ما يعكس شعبية هذه النماذج عالمياً.
وعلى صعيد توزيع السوق، أشار التقرير إلى أن استخدام النماذج أصبح أكثر تنوعاً مع نهاية 2025، حيث لم يتجاوز أي نموذج حصة 25%، بعد أن كان سوق النماذج في ديسمبر 2024 مهيمناً من قبل "ديب سيك".
بذلك، تؤكد الصين نفسها كقوة رئيسية تنافس الولايات المتحدة في تطوير الذكاء الاصطناعي على مستوى العالم.
 المصدر:
العربيّة
المصدر:
العربيّة